Описание
Elasticsearch – это одна из самых популярных поисковых систем в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска.
Назначение и основные функциональные возможности
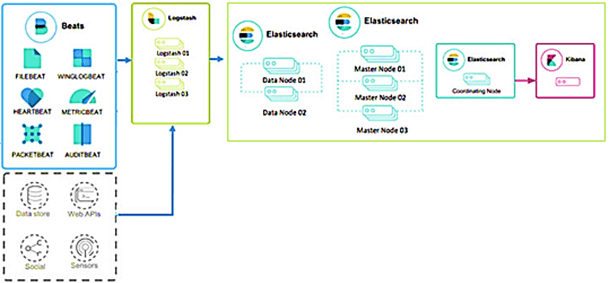
Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. ES является ядром ELK-стека (Elastic Stack), в состав которого, помимо Elasticsearch, входят следующие продукты [1]:
- Logstash– инструмент сбора, преобразования и сохранения в общем хранилище событий из различных источников (файлы, базы данных, логи и пр.) в реальном времени;
- Kibana– веб-интерфейс для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в его индексах ES через динамические панели мониторинга, таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени;
- FileBeat –агент на серверах для отправки различных типов оперативных данных в ES.
Из ключевых функциональных возможностей Elasticsearch стоит отметить следующие [2]:
- автоматическая индексация новых JSON-объектов, которые загружаются в базу и сразу становятся доступными для поиска, за счет отсутствия схемы согласно типичной NoSQL-концепции. Это позволяет ускорить прототипирование поисковых Big Data решений.
- поддержка восточных языков (китайский, японский, корейский);
- гибкость поисковых фильтров, включая нечеткий поиск и мультиарендность, когда в рамках одного объекта ES можно динамически организовать несколько различных поисковых систем;
- наличие встроенных анализаторов текста позволяет Elasticsearch автоматически выполнять токенизацию, лемматизацию, стемминг и прочие преобразования для решения NLP-задач, связанных с поиском данных.
Основные достоинства и недостатки Elasticsearch описаны здесь. Подчеркнем, что одним из главных недостатков ES считается склонность этой NoSQL-СУБД к утечкам данных из-за отсутствия встроенных средств обеспечения информационной безопасности, таких как система авторизации и ограничения прав доступа. Кроме того, после установки движок по умолчанию связывается с портом 9200 на все доступные интерфейсы, что открывает доступ к базе данных [2]. Подробнее об уязвимостях Elasticsearch читайте нашу отдельную статью.
История разработки и развития Elasticsearch
Основными ключевыми вехами в истории Elasticsearch считаются следующие:
- февраль 2010 года – Шай Бейнон (Shay Banon) выпустил первую версию системы под лицензией Apache0 [1];
- 2012 год – для коммерциализации проекта Бейнон основал нидерландскую компанию Elasticsearch BV [1];
- июнь 2014 года – стартап привлек внешнее финансирование в размере $104 миллионов [1];
- март 2015 года – компания Elasticsearch изменила название на Elastic [1];
- 2018 год – компания Elastic открыла исходный код своего коммерческого продукта X-Pack, который расширяет возможности Elasticsearch, включая обеспечение cybersecurity [3];
- 2019 год – компания Elastic сделала базовые функции обеспечения информационной безопасности ELK-стека бесплатными для всех пользователей, а не только тех, кто подписан на коммерческой основе [4].
Архитектура и принципы работы ES
ES обеспечивает горизонтально масштабируемый поиск с поддержкой многопоточности. Система основана на библиотеке Apache Lucene, которая предназначена для индексирования и поиска информации в любом типе документов. Все функции Lucene доступны через API-интерфейсы на JSON и Java. ES позволяет работать с GET- запросами в реальном времени, но не поддерживает распределённые транзакции. Бесшовная интеграция с Kibana гарантирует легкую управляемость по HTTP-интерфейсу
с помощью JSON-запросов за счет REST API.
В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер. Поисковые индексы можно разделить на сегменты, реплицировав каждый из которых несколько раз. Это обеспечивает отказоустойчивость системы. На узле ES-кластера может размещаться несколько сегментов. Каждый узел кластера действует как координатор для делегирования операций правильному сегменту с автоматической перебалансировкой и маршрутизацией. Связанные данные часто хранятся в одном и том же индексе из одного или нескольких первичных сегментов и нескольких реплик. После создания индекса количество первичных сегментов нельзя изменить. Долгосрочное хранение индекса обеспечивает шлюз, позволяя восстанавливать индекс при сбое сервера [5].
Где используется Elasticsearch: компании и Big Data проекты
Благодаря широкому набору функциональных возможностей, особенно полнотекстовому поиску по множеству языков и аналитике в реальном времени, Elasticsearch активно применяется в различных Big Data системах крупных и средних компаний по всему миру. Из наиболее известных зарубежных пользователей стоит отметить корпорации Netflix, IBM, Facebook, Amazon, GitHub, Wikimedia, CERN, Mozilla, Adobe [2]. В России ES применяется в проектах Альфа-Банка, облачной платформе автоматизации рекрутмента Potok.io, сети лабораторий «Центр молекулярной диагностики» (CMD), ИТ-компании «Инфотех-Групп» и многих других предприятий, о чем мы писали здесь.
Источники